Boost Memory¶
Add PanDA rules to boost memory¶
The retry_action is defined in https://panda-wms.readthedocs.io/en/latest/advanced/job_retry_module.html. We need to add rules in the PanDA database to boost memory.
Login to panda database to get the current retryaction_id and retryerror_id. Here are instructions:
select * from retryactions select * from retryerrors
Find different transExitCode, pilotErrorCode or other PanDA jobs’ error information for boost memory. To find the error codes, one way is from user reports (users report some error jobs). Another way is to analyse the job errors for a time period. For example, in the PanDA monitor page, click the ‘Errors” (the top menu line). PanDA will list all recent errors (sometimes you may need to add &days=30 in the URL to show more jobs). After that, you can scroll down to the Overall error summary section. Here you can click the item under Category:code. You will be redirected to a page that lists jobs with that error. (Frequently jobs with memory issues fail with some messages with words memory, kill, lost and so on).
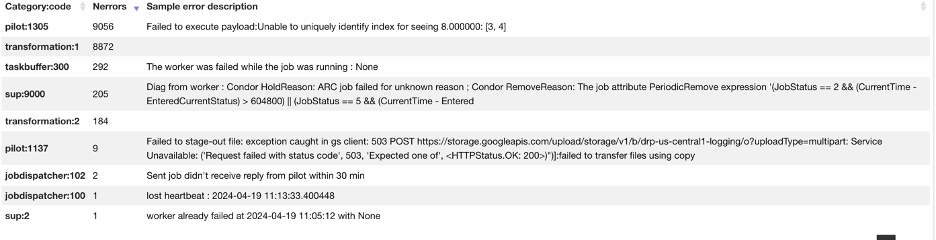
Add rules to boost memory. For Rubin, we found that exeErrorCode:137 and pilotErrorCode:1212 are caused by run out of memory. Here are instructins:
insert into retryactions(retryaction_id, retry_action, active, retry_description) values (1, 'increase_memory_xtimes', 'Y', 'Job ran out of memory. Increase memory setting for next retry.'); insert into retryerrors(retryerror_id, errorsource, errorcode, errordiag, active, retryaction, description) values(1, 'taskBufferErrorCode', 300, '.*The worker was finished while the job was starting.*', 'Y', 1, 'increase memory'); insert into retryerrors(retryerror_id, errorsource, errorcode, active, retryaction, description) values(1, 'exeErrorCode', 137, 'Y', 1, 'increase memory'); insert into retryerrors(retryerror_id, errorsource, errorcode, active, retryaction, description) values(2, 'pilotErrorCode', 1212, 'Y', 1, 'increase memory'); insert into retryerrors(retryerror_id, errorsource, errorcode, active, retryaction, description) values(3, 'transexitcode', 137, 'Y', 1, 'increase memory');
To monitor the logs in panda server (not jedi):
# how to find which machine to check # (1) go to the panda monitor page, for example https://usdf-panda-bigmon.slac.stanford.edu:8443/job?pandaid=18214833 # (2) click 'Show' -> 'Job Status log', you will find which machine that updates the job status kubectl exec -it -n panda panda-server-0 -- bash # or other panda servers ls /var/log/panda/panda-RetrialModule.log # check the database psql -h usdf-panda-server-rw.panda-db.svc.cluster.local -p 5432 -W -U rubin panda # password can be found in with 'env|grep PANDA_DB_PASSWORD' # check example jobs select pandaid, transexitcode, piloterrorcode, piloterrordiag, exeerrorcode, exeerrordiag from jobsarchived4 where pandaid=18106113; pandaid | transexitcode | piloterrorcode | piloterrordiag | exeerrorcode | exeerrordiag ----------+---------------+----------------+---------------------------------------------------------------------------------------------------------------+--------------+-------------- 18106113 | 137 | 1305 | Failed to execute payload:attempt to reduce the monitored value of monotonic rchar from 1546273273 to 1706939 | 0 | # check retry errors select * from retryerrors; retryerror_id | errorsource | errorcode | active | retryaction | errordiag | parameters | architecture | release | workqueue_id | description | expiration_date ---------------+----------------+-----------+--------+-------------+-----------+------------+--------------+---------+--------------+-----------------+----------------- 1 | exeErrorCode | 137 | Y | 1 | | | | | | increase memory | 2 | pilotErrorCode | 1212 | Y | 1 | | | | | | increase memory | # transexitcode: 137 is not marked as retry, to add it insert into retryerrors(retryerror_id, errorsource, errorcode, active, retryaction, description) values(3, 'transexitcode', 137, 'Y', 1, 'increase memory');